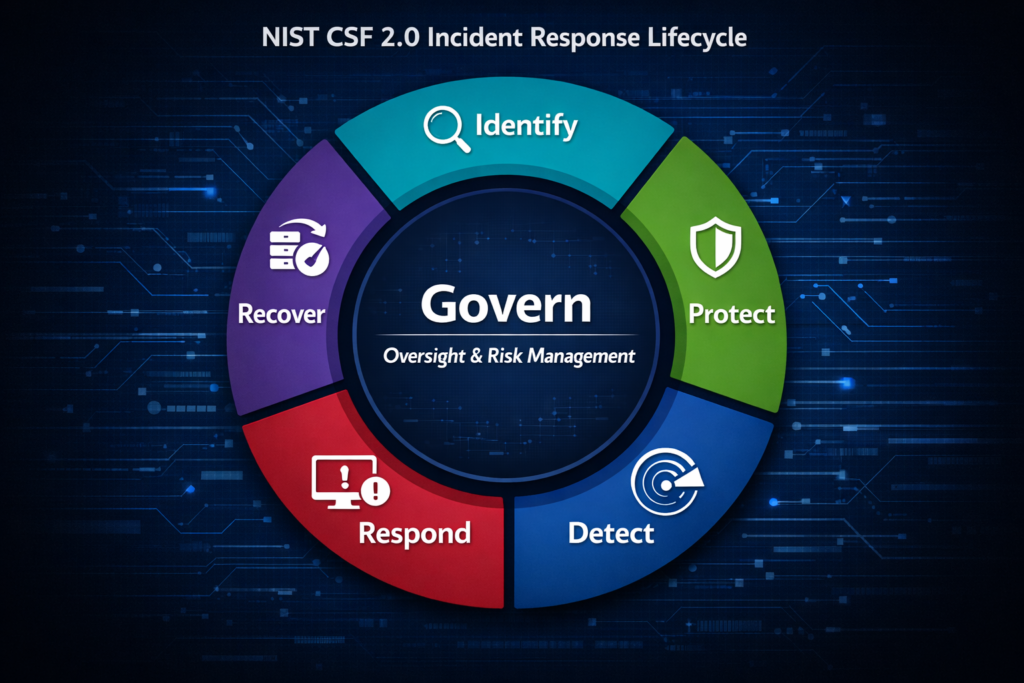
Most organisations have an IRP. Most discover it doesn’t work the moment they actually need it.
Not because the document is wrong, but because it was written for the organisation they used to be, not the one responding to an incident today.
Incidents in 2026 are cloud‑distributed, identity‑driven, SaaS‑entangled, and business‑impacting. Modern incident response is no longer a linear technical workflow, it is an organisational capability built on governance, resilience, and continuous improvement.
NIST’s Cybersecurity Framework (CSF) 2.0 reflects this shift. Instead of treating incident response as an isolated technical lifecycle, CSF 2.0 uses the overarching Govern function to shape how Respond and Recover integrate with the rest of your security posture.
This article is the blueprint.
Further NIST CSF 2.0 reading to help you build your own IRP.
- How to Build an Incident Response Plan: A Complete NIST CSF 2.0 Example. Here you will find a complete example of a NIST CSF 2.0 IRP.
- The Evolution of Incident Response: Updating the Classic NIST IRP to the 2026 Framework. Here is an explanation of how the traditional NIST lifecycle has shifted to the modern CSF‑aligned model
Step 1: Govern
The foundation of a modern IRP
Govern defines how the organisation makes decisions during an incident. It establishes authority, accountability, and communication. In CSF 2.0, governance isn’t a section, it’s the centre of the entire framework.
A modern IRP includes:
1.1 Purpose of the Incident Response Plan
Defines why the IRP exists and ensures every stakeholder understands its role in protecting business continuity.
1.2 Scope and Applicability
Clarifies exactly which systems, teams, and incident types the plan governs so there’s no ambiguity during escalation.
1.3 Definitions and Terminology
Establishes shared language to prevent miscommunication between technical and non‑technical responders.
1.4 Roles and Responsibilities
Ensures every team knows what they own during an incident, eliminating duplicated effort and gaps.
1.5 Incident Authority & Escalation Model
The most common IRP failure isn’t technical, it’s decision paralysis. Who can isolate a production system at 2am? Who can declare an incident? If this isn’t defined, containment is delayed by hours.
1.6 Regulatory, Legal, and Reporting Obligations
Include country specific requirements such as the Australian Notifiable Data Breaches (NDB) scheme and mandatory reporting timelines. These obligations shape your communication and evidence strategy.
1.7 Evidence Handling & Chain of Custody Requirements
Improper evidence handling can invalidate legal proceedings or insurance claims. This section must be explicit, not implied.
1.8 Governance Review & IRP Maintenance Schedule
How often the IRP is reviewed, updated, and approved.
Govern sets the rules of engagement. Everything else builds on this.
Step 2: Identify
Understanding what you’re protecting
Identify ensures the organisation has visibility into its environment and can recognise when something is wrong.
A modern IRP includes:
2.1 Asset Inventory & Critical Systems
Defines which systems are essential to operations and why they matter, ensuring responders prioritise the right assets during an incident.
2.2 Data Classification & Business Impact Mapping
Links data sensitivity to business impact so responders understand the consequences of exposure, loss, or corruption.
2.3 Threat Landscape & Common Attack Scenarios
Documents the attack patterns most relevant to your environment, helping responders recognise early indicators and avoid blind spots.
2.4 Third‑Party & Supply Chain Dependencies
Most organisations don’t actually know all their SaaS dependencies. This section often forces the first real discovery exercise.
2.5 Monitoring Sources & Visibility Requirements
Clarifies which logs, alerts, and telemetry sources responders can rely on, and where visibility gaps may slow detection.
2.6 Incident Severity Matrix
One of the most operationally important tools in the entire IRP. It determines whether someone calls the CISO at midnight or handles it in the morning.
Example (simplified):
| Severity | Impact Description | Core Modern Trigger (2026 Context) | Response Action |
| Sev 1 (Critical) | Total business disruption, data exfiltration, or ransomware. | Active IdP admin compromise / Cloud data drain. | Immediate IRT activation & War Room. |
| Sev 2 (High) | Localized disruption, lateral movement. | Privileged account compromise, EDR bypass attempts. | Alert CISO, triage within 1 hour. |
| Sev 3 (Medium) | Low-business-impact anomalies. | Single endpoint malware, suspicious single MFA swap. | SOC analyst triage during business hours. |
2.7 Incident Intake & Logging Requirements
Defines how incidents are reported and documented so nothing gets lost during handover or escalation.
Identify is about visibility. You can’t respond to what you can’t see.
2.8 Continuous Improvement (NIST CSF 2.0: ID.IM)
Continuous Improvement maps directly to the ID.IM (Improvement) category within the Identify function of NIST CSF 2.0. CSF 2.0 treats improvement as a core readiness capability, not something performed only after an incident. By placing Continuous Improvement within Identify, reinforces that lessons learned, capability uplift, and governance feedback loops are foundational to incident preparedness.
A mature IR capability is measured not by how well the first incident is handled, but by how much better the organisation performs during the second. Continuous Improvement ensures the organisation learns, adapts, and evolves after every incident.
2.8.1 After‑Action Review Process
The organisation conducts two structured review activities after every incident.
Hot Wash (within 24–48 hours)
A rapid, informal debrief focused on immediate observations:
- what happened
- what worked
- what failed
- operational friction points
- emotional or team‑level insights
The goal is to capture raw feedback while the incident is still fresh.
Formal Post‑Incident Review (PIR)
A structured, documented review completed within 5 business days.
The PIR includes:
- incident timeline
- root cause analysis
- control failures and gaps
- communication effectiveness
- response delays
- containment and recovery performance
- recommendations for improvement
2.8.2 Incident Reporting Template
NIST uses a standardised incident reporting template to ensure consistency and reduce cognitive load during high‑pressure situations.
The template includes:
- incident summary
- severity classification
- affected systems and data
- timeline of events
- actions taken
- evidence collected
- communication log
- root cause
- lessons learned
- remediation actions
- ownership and deadlines
2.8.3 Root Cause Analysis Requirements
Every Medium and High severity incident requires a formal Root Cause Analysis (RCA).
Recommended RCA Methods
- Five Whys
- Contributing Factors Analysis
RCA Outputs Must:
- identify the primary cause
- identify contributing causes
- map each cause to a failed or missing control
- recommend specific improvements
Low Severity Incidents
Low severity incidents do not require individual RCAs. They are reviewed collectively during quarterly IRP review meetings to identify patterns and systemic weaknesses.
2.8.4 Control Improvements and Remediation Tracking
Lessons learned must translate into implemented changes.
Maintain a Remediation Register that tracks:
- identified issues
- recommended improvements
- control owners
- deadlines
- status (open, in progress, blocked, complete)
- risk rating
- verification evidence
This prevents “PIR theatre” where issues are identified but never fixed.
2.8.5 IRP Update and Governance Review Cycle
The IRP must evolve with the organisation, not lag behind it.
IRP Review Requirements
- annual full review by ICT Management, SOC, and Risk Advisor
- post‑incident updates after every Medium or High severity incident
- version control maintained by ICT Management
- executive approval required for major revisions
Governance Alignment
The IRP review cycle ensures alignment with:
- NIST CSF 2.0
- ACSC Essential Eight
- organisational risk appetite
- technology changes
- regulatory obligations
- lessons learned from real incidents
Continuous Improvement ensures the organisation becomes more resilient with every incident, not just compliant.
Step 3: Protect
Readiness and hardening
Protect covers proactive measures that reduce the likelihood or impact of an incident. This section isn’t here to restate your security program, it documents the baseline assumptions your response procedures depend on.
For example, your containment workflow may assume MFA is enforced. If it isn’t, an identity compromise incident becomes significantly harder to contain and your IRP must reflect that reality.
A modern IRP includes:
3.1 Preventive Security Controls
Documents the minimum security baseline your response procedures assume. If these controls fail, your IR timeline changes dramatically.
3.2 Backup & Recovery Readiness
Use the 3‑2‑1‑1 rule: 3 copies, 2 media types, 1 offsite, 1 immutable/air‑gapped. Attackers increasingly target backups directly. Immutable or un-deletable copies are now non‑negotiable.
3.3 Patch & Vulnerability Management
How vulnerabilities are tracked, prioritised, and remediated.
3.4 Access Control & Identity Security
Least privilege, privileged access workflows, identity governance.
3.5 Security Awareness & Training Program
Mandatory training, phishing simulations, SOC upskilling.
3.6 Tabletop Exercises & IRP Testing
Annual simulations to validate the plan.
Protect is the difference between a difficult incident and a catastrophic one.
Step 4: Detect
Identifying potential incidents
Detect is where monitoring, alerting, and triage occur.
A modern IRP includes:
4.1 Detection Methods & Alerting Sources
Defines the signals your organisation relies on SIEM alerts, XDR detections, anomaly detection, and threat intel. This ensures responders know where detections originate.
4.2 Triage Workflow
Most IRPs go vague here. Don’t.
Modern triage flow: Alert fires → L1 triage & context enrichment → True positive confirmed → Ticket created → L2 severity assessment → IRT activation (if Sev2+)
4.3 Incident Classification & Prioritisation
Ensures responders use consistent criteria: severity, impact, urgency to avoid misclassification and escalation delays.
4.4 War Room Activation Criteria
In 2026, a “war room” is usually a Teams/Slack bridge with a named Incident Commander, not a physical room.
4.5 Initial Notification Procedures
Clarifies who must be notified at each severity level so no one is left guessing during early response.
4.6 Logging Requirements During an Incident
Ensures logs are preserved for investigation and legal defensibility.
Detect is where potential issues become confirmed incidents.
Step 5: Respond
Containment, analysis, and coordination
Respond stabilises the incident and prevents further harm.
A modern IRP includes:
5.1 Response Objectives
What the organisation aims to achieve during response.
5.2 Initial Response Actions
Evidence preservation, log collection, forensic imaging.
5.3 Containment Strategies
Distinguish between:
- Short‑term containment: stop the bleeding
- Long‑term containment: stabilise while investigation continues
- Identity containment: token revocation, disabling compromised IdP accounts, resetting MFA, applying emergency conditional access policies
5.4 Investigation & Analysis Procedures
Root cause, attacker behaviour, scope, impact.
5.5 Communication Plan
Break into four audiences:
- Internal
- Executive
- Legal/regulatory
- Customer/public
Each requires different tone, timing, and detail.
5.6 Decision‑Making Framework
Who approves containment, eradication, and public communication.
5.7 Coordination with External Stakeholders
Include ASD/ACSC for Australian readers.
5.8 Documentation Requirements During Response
What must be recorded and by whom.
Respond is where the organisation takes control of the incident.
Step 6: Recover
Restoration and resilience
Recover focuses on restoring normal operations safely and preventing reinfection.
A modern IRP includes:
6.1 Recovery Objectives
Defines what “restored” actually means, not just operational, but secure and stable.
6.2 System Restoration Procedures
Rebuilds, clean images, validated backups ensuring compromised systems aren’t simply put back into production.
6.3 Backup Validation & Clean Restore Requirements
Restoring from a compromised backup is one of the most common reinfection paths. Validate backups in isolation before production.
6.4 Post‑Restoration Hardening
Ensures restored systems return stronger than they were before the incident.
6.5 Business Continuity Integration
Coordinates with BCP/DR teams so recovery aligns with business priorities.
6.6 Return‑to‑Service Criteria
A formal sign‑off checklist:
- Security team approval
- Business owner approval
- Monitoring active
- No IOCs present
6.7 Communication of Recovery Status
Keeps staff, executives, and customers informed as systems return to service.
Recover is not the end, it is part of a continuous cycle.
Next Week: The TayvenSec Modern IRP Template
I’m not just giving you theory. Next week, I’m releasing the exact, copy‑paste TayvenSec IRP Template built natively for modern operations.
Includes:
- Fully drafted text for all 7 sections
- Playbooks
- Communication scripts for Australian NDB timelines
- Ready‑to‑use Post‑Incident Review (PIR) dashboards
- Severity matrices and governance workflows
Bookmark this page or subscribe so you don’t miss the drop.
Closing
The goal isn’t just to write an IRP, it’s to build an incident response capability that actually works when it matters. By the end of this series, you’ll have a complete, modern IRP that any organisation can adopt or adapt with confidence.
References
The NIST Cybersecurity Framework (CSF) 2.0 Documentation
Continue Reading
Check out my other articles! If you enjoyed this one, you’ll probably like the rest of my cyber stories, guides, and breakdowns too.
The Evolution of Incident Response: Updating the Classic NIST IRP to the 2026 Framework